| DEDECMS(织梦内容管理系统)采集不了的原因可能有很多,以下是一些常见的原因和解决方法: 网站设置问题:检查是否设置了正确的采集规则和路径,确保DEDECMS能够正常访问目标网站,并且有足够的权限进行采集操作。 网站反爬虫机制:有些网站为了保护自己的数据安全,会设置反爬虫机制,例如增加验证码、限制并发采集等。这时可以尝试使用代理服务器进行采集,或者通过破解验证码的方式绕过网站的反爬虫机制。
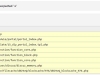
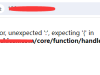
DEDECMS采不到相对地址的网址 织梦采集相对路径出错解决方案 问题描述 当采集目标文章中列表或者分页信息是绝对路径时,DEDE可以正确采集。 当采集目标文章中列表或者分页信息是相对路径,但是以 ‘/’开头(如 /2012/0328/1943.html)DEDE也可以正确采集。 当采集目标文章中列表或者分页信息是相对路径,但不是以 ‘/’开头(如 2012/0328/1943.html)DEDE就不能正确采集了。 解决方案 问题的根源出在 dedehtml2.class.php 中的 FillUrl 函数上。 大概在394行左右: if( strlen($surl) < 7 ) { $okurl = $this->BaseUrlPath.'/'.$surl; } else if( strtolower(substr($surl,0,7))=='http://' ) { $okurl = preg_replace('/^http:///i', '', $surl); } else { //$okurl = $this->BaseUrlPath.'/'.$surl; $okurl = $this->HomeUrl.'/'.$surl; } 被注释掉的代码是原始的,增加一行问题就解决了 网站结构问题:有时候在采集网站数据时,可能会遇到一些复杂的网页结构,导致采集工具无法正确解析。在这种情况下,可以尝试使用其他采集工具,或者手动编写自定义的采集脚本来获取所需的数据。 Robots.txt文件限制:有些网站会在Robots.txt文件中设置禁止爬取的规则,从而导致DEDECMS无法采集。用户可以通过访问网站的Robots.txt文件来检查是否有相关的限制。如果存在限制,则可以尝试联系网站管理员解决或调整DEDECMS的爬取策略。 服务器限制:如果网站服务器对采集有限制,可以尝试使用代理服务器。代理服务器可以帮助我们隐藏真实的IP地址,绕过服务器的限制。可以通过设置代理服务器的方式,让DEDECMS使用代理进行采集。可以选择一些稳定的代理服务供应商,确保采集的顺利进行。 PHP环境配置问题:在某些情况下,PHP环境中的函数可能会被禁用,导致DEDECMS无法正常采集。例如,fsockopen函数被禁用可能会导致采集失败。解决办法是修改程序或PHP环境配置文件(php.ini),将禁用函数(如fsockopen)重新启用。 请注意,以上方法仅供参考,具体的解决方法可能因情况而异。如果问题仍然存在,建议寻求专业人士的帮助或咨询DEDECMS的技术支持团队。 |